RIO Education Data Factory Extension
Table of Contents
Overview
The RIO Education Data Factory is used to load a set of sample data for RIO Education into an org. It is intended be used with a fresh install of RIO Education to quickly provide new users with data that allows them to test out how RIO Education works.
How it works
RIO Education Data Factory data flow
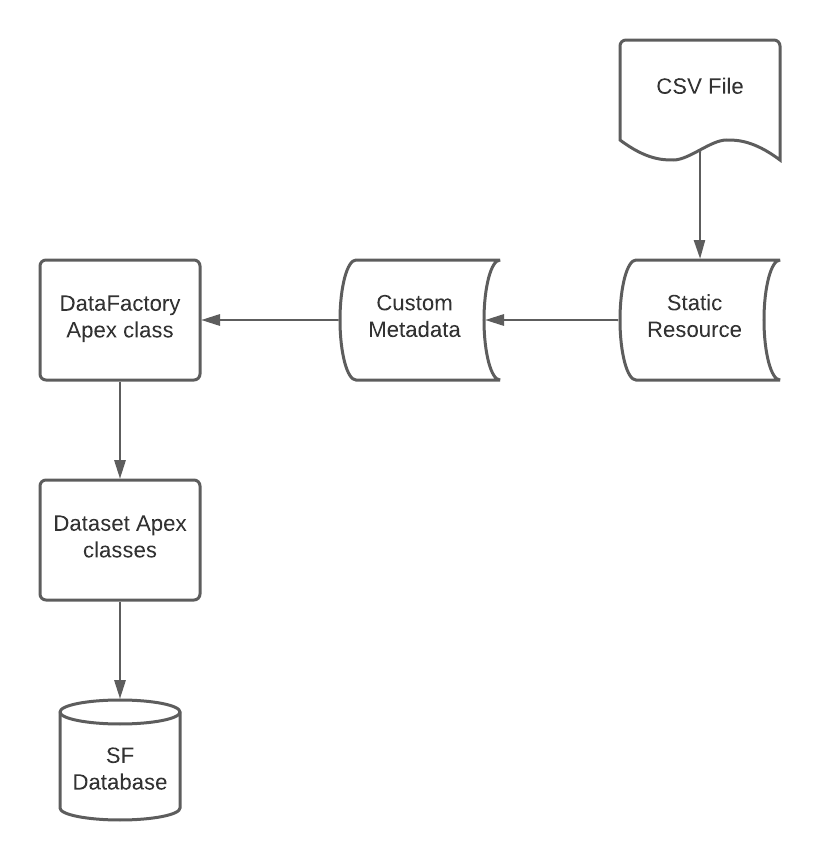
This diagram shows the stages that data goes through in the Data Factory program. These stages are described in detail below:
CSV files and static resources
The data that will be loaded by the Data Factory is all stored in CSV files. Each CSV file will contain the data for one 'data set', with the rows of the file representing records and the columns representing fields. These CSV files are stored in Salesforce as Static Resources.
Custom metadata
The Data Factory makes use of Custom Metadata Type called RIO Education Data Factory Mapping. These mappings are used to associate a CSV Static Resource with any other information needed to load that data set into Salesforce. Each mapping represents a single data set. The mapping metadata type has a series of custom fields that are described below.
| Field Label | API Name | Description |
|---|---|---|
| Active? | rio_ed_df__Active__c |
The Active? field is a checkbox that indicates whether or not this particular data set is active. Only active data sets will be loaded by the Data Factory. If this field is unchecked, the data set will not be loaded. This allows users to remove data sets from the standard Data Factory sample data, allowing them to customize their own Data Factory. Customization is described in a later section of this article, including its limitations and potential problems. |
| Data Group Name | rio_ed_df__Data_Group_Name__c |
In later releases, there is a plan to give users the option to load data in a series of individual data groups - each group containing several data sets. This field is not used in v1 of the Data Factory. |
| File Location | rio_ed_df__File_Location__c | The name of the Static Resource containing the CSV file that contains the data for this data set. |
| Object Name | rio_ed_df__Object_Name__c | The API name of the kind of object that this data set loads. Each data set will only load data for a single object. |
| Sequence | rio_ed_df__Sequence__c | The sequence is what defines the order in which data sets will be loaded. Order is crucially important as many data sets have dependencies on other data sets and will not work if loaded out of order. |
| Type | rio_ed_df__Type__c | This field is presently only used to separate mappings that have Session Time as their target object into Session Times for template sessions and Session Times for class sessions. Because these require different back-end functionality for loading, they cannot be loaded in the same data set. Further releases may require this field to be used for other objects. |
Apex classes
The Apex functionality for the Data Factory consists of a main DataFactory class and separate classes for each kind of object that is inserted. For example Dataset_ACC handles data sets that have Account as their target object.
Note that this is one class per target object, not one class per data set. For example, the Educational Institution Data Set and the University Department Data Set both use Dataset_ACC, as they both insert account objects. The only object that requires more than one class is Session Time, which is split into Dataset_ST_Temp and Dataset_ST_Class.
DataFactory class
The main DataFactory class contains the generate data methods that can be run by the user. Currently the only method is generateAllData(), which simply loads all the sample data at once. This method will retrieve all the mappings for the data that is being loaded and then for each mapping, will call the generateData method from the appropriate Dataset class for that target object.
Dataset classes
There are separate dataset classes for each kind of object that is inserted. For example Dataset_ACC handles data sets that have Account as their target object. Note that this is one class per target object, not one class per data set. For example, the Educational Institution Data Set and the University Department Data Set both use Dataset_ACC, as they both insert account objects.
The only object that requires more than one class is Session Time, which is split into Dataset_ST_Temp and Dataset_ST_Class, because the process of inserting Session Times is different depending on whether the associated Session is a Template or Class record type. The code for the DataFactory uses upsert not insert, meaning that the DataFactory may be run multiple times. This may be useful if some data loaded by the Data Factory is accidentally deleted. However, caution must taken when modifying any data that is loaded, as running the Data Factory again will restore it to its initial state.
Each dataset class contains a generateData method that is called by the main DataFactory class and converts a CSV file into records of the respective object and then upserts those records. The current dataset classes can be seen below.
| Dataset Class | Target Object |
|---|---|
| Dataset | None. This is the abstract parent class that the other dataset classes extend. |
| Dataset_ACC | Account. |
| Dataset_CO | Course Offering. |
| Dataset_COURSE | Course. |
| Dataset_CT | Contact. |
| Dataset_FAC | Facility. |
| Dataset_FEE | Fee. |
| Dataset_FS | Fee Schedule. |
| Dataset_FST | Fee Schedule Term. |
| Dataset_HOL | Holiday. |
| Dataset_PCR | Program Course Requirement. |
| Dataset_PPATH | Program Pathway. |
| Dataset_PPLAN | Program Plan. |
| Dataset_PR | Plan Requirement. |
| Dataset_PU | Pathway Unit. |
| Dataset_QF | Qualified Faculty. |
| Dataset_SESS | Session. |
| Dataset_ST_Class | Session Time. |
| Dataset_ST_Temp | Session Time. |
| Dataset_TB | Time Block. |
| Dataset_TERM | Term. |
| Dataset_TH | Term Holiday. |
Note that there is one dataset class that performs additional functionality other than just upserting records. RIO Education contains a validation rule on the Fee Schedule object that means that Fee Schedules cannot be approved unless they have at least one related Fee Schedule Term.
Because records for these objects are inserted by different data sets, the Dataset_FS class will always set the Status field on inserted Fee Schedule records to 'Draft'. There is then additional functionality in the Dataset_FST class in which after the Fee Schedule Term records are loaded, any parent Fee Schedules for those records are approved.
How to use it
The RIO Education Data Factory is presently only able to be used by running an Apex script. Future releases will allow it to be run using a UI interface.
Before running Data Factory script
- RIO Education managed package must be installed in the org.
- RIO Education Data Factory managed package must be installed in the org (see installation section).
- Make sure you set up a custom tab for the hed__Error__c object. This is where the success and failure messages will be reported.
Running the Data Factory script
- Log in to your org with both the RIO Education and RIO Education Data Factory packages installed.
- Click on the gear icon in the top right and select Developer Console.
- Click Debug and select Open Execute Anonymous Window (or press CTRL + E).
- Enter the following Apex code and then click Execute.
rio_ed_df.DataFactory.generateAllData();
- Check that the desired data has been inserted. You can either manually check that the records have been added to the database, or you can navigate to the errors tab you set up earlier. If the data load was successful, an error should have been added with a message containing a list of what data sets were inserted.
Note that while this is recorded in the hed__Error__c object, this does not mean an actual error has occurred. This was just the chosen method of reporting messages for both success and failure.
- If the data has not been added, navigate to the errors tab you set up. An error should have been added with a message containing the data set that failed to load and the error that occurred.
Customization
The Data Factory comes pre-packaged with several sample data-sets. However, we understand that many customers will want to customize the data that their Data Factory loads. The Data Factory does allow some degree of customizability, however there are limitations that need to be taken into account.
Adding new data sets
Users are free to add both new static resources and new custom metadata records. However, it is not possible for them to create new dataset Apex classes. This essentially means that users are free to add new data sets to the sample data, but the target object for their new data set can only be one of the objects supported by the existing dataset classes. See the Dataset classes in the How it works section for a list of supported objects.
Also, new static resources and CSV files must abide by a set of rules (this section). If these rules are not followed, correct behaviour is not guaranteed.
Removing existing data sets
Neither static resources, custom metadata records or Apex dataset classes can be deleted by the user after the managed package is installed. This means it is not possible to actually delete existing data sets. However, each custom metadata record has an Active? checkbox field. This field can be unchecked on any datasets that the user does not wish to load. The Apex code will ignore datasets that have an unchecked active flag. These data sets can be re-added at any time by simply editing their active flag to be checked.
Be careful when deactivating data sets, as if the deactivated data set has dependent data sets that have not been either deactivated themselves or are already loaded in the database, attempting to run the Data Factory will cause an error.
Editing existing data sets
It is not possible for a user to edit existing static resources or Data Factory Apex classes. However, it is possible for users to edit certain fields of existing custom metadata records. Specifically, all custom fields may be edited. This means that the label and name of the mapping cannot be changed.
This has the potential to cause problems. For example, changing a data set to insert something completely different may seem like a viable alternative to creating a new data set, but because the labels and names cannot be changed, you may end up with confusing inconsistencies. For example, changing the Academic Program Data Set to insert something other than academic programs will make debugging very confusing and is not recommended.
Another potential problem could arise from fields that do not match up with each other. For example, if you edited a data set with a target object of Account and changed the static resource to be CSV file that inserted a different kind of object, you would get an error because the code would be unable to translate the CSV file into valid account records.
Generally speaking, editing the custom metadata directly should only be done for small changes, such as changing the static resource to load different records or to change the sequence number. Any changes that will change the target object or type should instead be done by removing the existing data set using the active field and creating a new data set with the new desired functionality. Any direct edits to custom metadata records should conform to the rules.
Rules
These are the rules that must be followed when creating or editing CSV files, static resources, and custom metadata records.
CSV files
- Columns in the CSV file represent fields, rows represent records.
- The top row in the CSV file should be the field names.
- Make sure to use API names for all field headers and not labels.
- Make sure to include all fields that you want to insert. With some exceptions, only fields present in the CSV file will be populated.
- All fields populated automatically (eg. by formulas, triggers, workflows etc.) should still be populated.
- The Status field on Fee Schedule objects is always set as 'Draft' whether it is included in the CSV file or not.
- When inserting Fee Schedule Terms, the Status field on all parent Fee Schedule objects is set to 'Approved'.
- For lookup fields, do not include the Salesforce Id as the value. Instead, include the External Id of the desired record. For example, to link the Course BUS101 to the School of Business, simply write 'School of Business' under the field hed__Account__c in the CSV file. The code will translate this into the appropriate Salesforce Id.
- CSV files should only contain records of a single object. For example, Accounts and Contacts should be inserted using separate CSV files.
- CSV files should only contain records of a single record type. For example, Educational Institutions and Academic Programs should be inserted using separate CSV files.
- CSV files containing session time records must be separated depending on whether their parent sessions are Templates or Classes. There is different insert functionality for each.
- Further separation of records into data sets is up to the user, as long as they meet the requirements above.
- The Data Factory can only load data for the following objects. Attempting to load CSV files with records intended for other objects will result in incorrect behaviour.
- Account.
- Contact.
- Course.
- Course Offering.
- Facility.
- Fee.
- Fee Schedule.
- Fee Schedule Term.
- Holiday.
- Pathway Unit.
- Plan Requirement.
- Program Course Requirement.
- Program Pathway.
- Program Plan.
- Qualified Faculty.
- Session.
- Session Time.
- Term.
- Term Holiday.
- Time Block.
Static resources
- Existing static resources follow the naming convention Dataset_Name_CSV, however there is no requirement for users to keep this convention.
- Ensure that the CSV file attached to the static resource follows the CSV file rules.
Custom metadata records
- Ideally, the Label should be an accurate description of what the data set is. For example, in the Data Factory data set, the record for academic programs is called Academic Program Data Set. While breaking this rule will not cause an error, inconsistent or non-descriptive names can cause confusion, especially when it comes to debugging.
- All the metadata records that come pre-packaged with the Data Factory follow the Label naming convention of <Data Set Name> Data Set, for example Educational Institution Data Set. However, there is no requirement for users to keep this convention.
- Make sure to check the Active? field on any data sets you want to be loaded. The Data Factory will ignore inactive data sets.
- Ensure the file location is the name of a valid static resource that follows the static resource rules.
- Data Group Name can be ignored for now as data groups are not supported in this release version. However, users are free to start grouping their custom data into data groups now if they would like.
- The Object Name field should refer to the object that the CSV file contains records of.
- Object Name should be the API name of the object (for example, use hed__Course_Offering__c, not Course Offering).
- Sequence is used to determine what order data sets are inserted. This is very important as some data sets may require other data sets to be inserted first. Any data set with a lower sequence number will be inserted before a data set with a higher sequence number. Any data sets with equal sequence numbers can be inserted in any order.
For example, all data sets with sequence 4 are guaranteed to be inserted before any data sets with sequence 5. The pre-packaged data has a simple sequence system where each of the 29 data sets is simply numbered 1 to 29 based on the order they are inserted. Users are free to use their own numbering system as long as they take the above behaviour into consideration.
- The Type field is only used for inserting Session Times. When inserting Session Times, the Type field must be set to either 'Template' or 'Class', depending on whether the parent sessions are template or class sessions. Leaving the field blank will result in the data not being inserted. Providing the wrong type will lead to incorrect behaviour. The Type field does not do anything for data sets for other objects and so should be left blank.
Future releases
This is only Version 1 of the RIO Education Data Factory. Here are some of the features that are planned to be added in future releases.
Data groups
Future releases of the Data Factory will feature the ability to group data sets into different data groups. This will enable users to load specific data groups at one at a time, instead of loading all the data at once.
The current plan is for the initial data groups to follow the structure of the RIO Challenges, with each challenge corresponding to a different data group. It should be noted that data groups, like data sets will have dependencies.
For example, loading the data for RIO Challenge 5 will likely cause an error if the data for RIO Challenge 4 is not already present. To fix this, it is likely that loading a data group will also load all data from previous data groups, so loading Challenge 5 will also load Challenge 1 - 4. Because the Data Factory uses upsert, this should not cause an error if the previous data groups were already loaded, but it will reset them if they have been modified manually.
Delete data
Future releases of the Data Factory will feature the ability to delete some or all of the data that has been loaded by the Data Factory. We will need to ensure that this method does not accidentally delete any data in the org that was not loaded by the Data Factory. This will probably be done using some sort of watermark when records are loaded. We will also need to handle deleting child records. What kinds of data will be allowed to be deleted (individual records, data sets, data groups etc) has yet to be determined.
User interface
Future releases of the Data Factory will feature a Lightning Component UI. This UI will allow users to graphically select what data group they want to load and then load the data by clicking a button, rather than running an Apex script. It will also allow deletion of data to be done in a similar way.
Improved error handling
We will look to make improvements on error handling in future versions.
Installation
Installation links
Production - https://login.salesforce.com/packaging/installPackage.apexp?p0=04t5g0000005S6K
Sandbox - https://test.salesforce.com/packaging/installPackage.apexp?p0=04t5g0000005S6K